Artificial Intelligence
Sharpen thinking. Take responsibility for AI. Own your decisions.
AI changes, above all, how people judge.
Because outputs appear plausible, fast and authoritative, error monitoring declines without anyone noticing.
In one study, 79 per cent of knowledge workers surveyed reported expending less cognitive effort since adopting AI than they did before (Lee et al., 2025). The real risk lies in the interaction itself.
I help leaders and organisations understand this shift and build decision systems that work even with AI in the room.
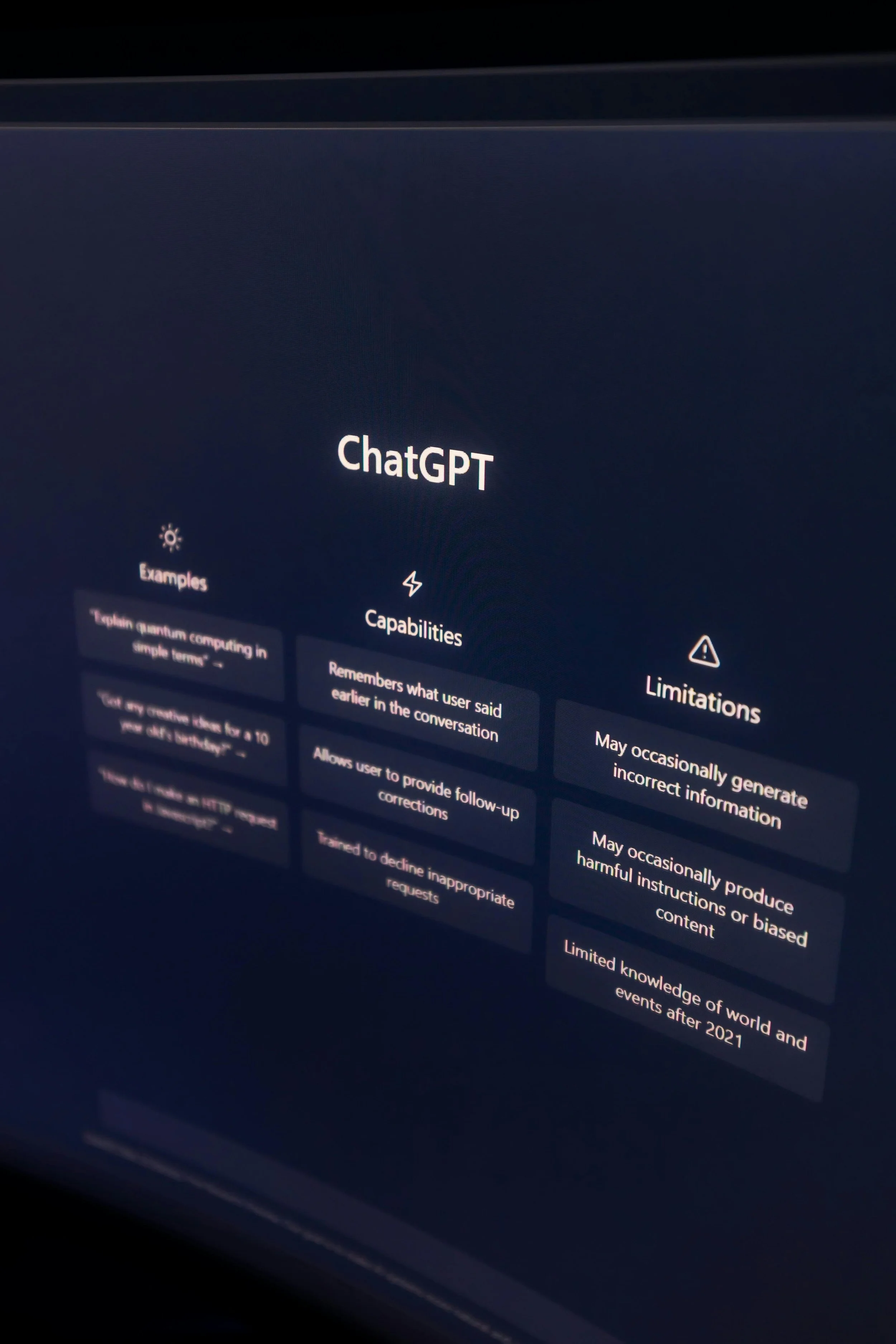
Where judgement quality breaks down in AI contexts
Automation bias and declining error monitoring
AI outputs feel more objective than human assessments because they come from a system.
This leads to results being questioned less actively, errors surfacing later and accountability becoming more diffuse across teams. Automation bias is well established in the research and occurs even among experienced professionals who know that AI systems make mistakes (Goddard, Roudsari & Wyatt, 2012).
Knowing that a system is fallible does not protect against the effect.
Diffusion of responsibility
When a decision appears technically mediated, it becomes easier to set aside critical consequences and shift responsibility onto the AI.
This is a cognitive mechanism that operates regardless of how competent or conscientious the people involved are. It is particularly pronounced when decision processes do not clearly define who checks what on what basis.
Where that clarity is missing, no one takes on the review, because everyone assumes someone else will.
Illusion of understanding
AI outputs are linguistically smooth and superficially plausible. This creates the feeling of having understood the content, even when no real scrutiny has taken place.
This is a structural feature of interacting with systems that are very good at signalling competence.
Those who do not actively assess whether an output is technically sound instead unconsciously assess whether it feels coherent. Those are two different questions, and they often have different answers.
Model limits and evaluation problems
The documented capability of an AI model depends on the tests it has been subjected to. Every new implementation brings fresh uncertainty about where the actual performance limits lie, particularly in domain-specific or high-stakes contexts.
Those who do not realistically assess these limits make decisions on a foundation they consider more stable than it is. And because errors in AI systems tend to occur not randomly but systematically, they can accumulate across many decisions before they become visible.
-
Goddard, K., Roudsari, A., & Wyatt, J. C. (2012). Automation bias: A systematic review of frequency, effect mediators, and mitigators. Journal of the American Medical Informatics Association, 19(1), 121–127. https://doi.org/10.1136/amiajnl-2011-000089
Ikeda, S. (2024). Inconsistent advice by ChatGPT influences decision making in various areas. Scientific Reports, 14(1), 15876. https://doi.org/10.1038/s41598-024-66821-4
Kosmyna, N., Hauptmann, E., Yuan, Y. T., Situ, J., Liao, X.-H., Beresnitzky, A. V., Braunstein, I., & Maes, P. (2025). Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task(arXiv:2506.08872). arXiv. https://doi.org/10.48550/arXiv.2506.08872
Lee, H.-P. (Hank), Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., & Wilson, N. (2025). The Impact of Generative AI on Critical Thinking: Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 1–22. https://doi.org/10.1145/3706598.3713778
Logg, J. M., Minson, J. A., & Moore, D. A. (2019). Algorithm appreciation: People prefer algorithmic to human judgment. Organizational Behavior and Human Decision Processes, 151, 90–103. https://doi.org/10.1016/j.obhdp.2018.12.005
Risko, E. F., & Gilbert, S. J. (2016). Cognitive Offloading. Trends in Cognitive Sciences, 20(9), 676–688. https://doi.org/10.1016/j.tics.2016.07.002
Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., & Farajtabar, M. (2025). The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity(arXiv:2506.06941). arXiv. https://doi.org/10.48550/arXiv.2506.06941
How I work
I do not advise on individual AI models or tools. I work where domain expertise is in place but working with AI is changing how people judge.
To do that, I make bias effects and accountability structures tangible within the client's own context, drawing on real cases and research findings.
From there, we develop together evaluation standards, clear responsibilities and governance structures that hold regardless of which model is in use.
Short formats
A 20-minute input for internal training or professional events
A 30 to 60-minute keynote, with or without Q&A
Workshops
90 to 180 minutes, interactive and case-based
Suited to leadership teams and decision-making groups who want to sharpen how they handle AI-assisted decisions at a structural level.
Advisory
Sparring and ongoing advisory work for leaders, as well as facilitated clarification sessions for decision-making groups
The focus is on governance standards that hold even as new models are introduced.
Who this is for
This work is for leaders and executive teams who want to treat AI use as a governance question,
for teams who work with AI outputs daily and need structured evaluation standards,
and for organisations that want to define accountability around AI-assisted decisions clearly before mistakes happen.
What all of them share is the question of why AI implementations can lead to worse decisions despite thorough preparation.
Read more on this